
Es fácil que se confundan los términos y la aplicación de la Inteligencia Artificial, el Machine Learning y el Deep Learning como una misma cosa.
Vamos a tratar de diferenciarlos.
Es fácil que se confundan los términos y la aplicación de la Inteligencia Artificial, el Machine Learning y el Deep Learning como una misma cosa.
Vamos a tratar de diferenciarlos.
Es importante entender que el Aprendizaje Profundo (Deep Learning) es parte del Machine Learning, así como este, es parte de la Inteligencia Artificial.

Puedes descargar la descripción del esquema Niveles de la IA, en formato texto, haciendo clic aquí.
Centrándonos en el Aprendizaje Automático (ML), vamos a ver algunas de sus características. Para ello vamos a tomar como ejemplo la "Máquina que predice el futuro" del apartado 3 que en realidad es un símil para entender algunos conceptos del ML.
Estos son los 3 tipos de Machine Learning :
Este tipo de aprendizaje requiere datos de objetos etiquetados para que puedan aprender a realizar su trabajo. Es decir, el sistema informático es capaz de generar conocimientos en base a unos datos ya etiquetados como por ejemplo miles de fotografías de perros cuya etiqueta identifica a qué raza pertenecen.
En este proceso, se incluyen datos de los cuales ya se saben los resultados, en base a ellos, la máquina se va entrenando y detectando patrones con los que aprenderá a clasificar los nuevos datos que se le añadan posteriormente.
Es un método de aprendizaje automático muy utilizado en herramientas con las que tenemos contacto a diario como detectores de correo spam, imágenes en captchas, etc.
Este tipo de Machine Learning trabaja con datos no etiquetados y de los cuales no se conoce el resultado con antelación.
Una técnica muy conocida de Aprendizaje No Supervisado, el Clustering. De forma previa no se posee una estructura lógica de los Datos, sin embargo y gracias a este modelo, estos datos se van segmentando y agrupando en función algunas características similares.
Este tipo de análisis se utiliza en estudios de mercado, en los que, a partir de toda una serie de características, el Machine Learning es capaz de encontrar un número de grupos con características similares definido por el Científico de Datos.
Forma parte de lo que conocemos como aprendizaje profundo (Deep Learning). Su objetivo principal es construir modelos que optimicen el rendimiento en base a resultados ya obtenidos anteriormente.
Para ello, su sistema de aprendizaje esta basado en recompensas. Si la máquina lo hace bien, recibe un premio (valor positivo) si lo hace mal una “penalización” (valor negativo).
Gracias a este modelo, la máquina es capaz de entrenarse hasta dar con una buena solución y además, aprende a tomar las decisiones “acertadas”.
¿Crees que nuestra MPF puede pertenecer a este grupo?
Recuerda activar los subtítulos si lo necesitas.
Para crear Inteligencia Artificial hay dos fundamentos básicos :
El algoritmo proporciona las instrucciones para la máquina y los datos permiten a la máquina aprender a emplear esas instrucciones y perfeccionar su uso.
Los algoritmos se pueden clasificar en dos tipos:
Los principales algoritmos que identifican y aprenden de patrones son:
Un árbol de decisión es un esquema de los posibles resultados de una serie de decisiones relacionadas.
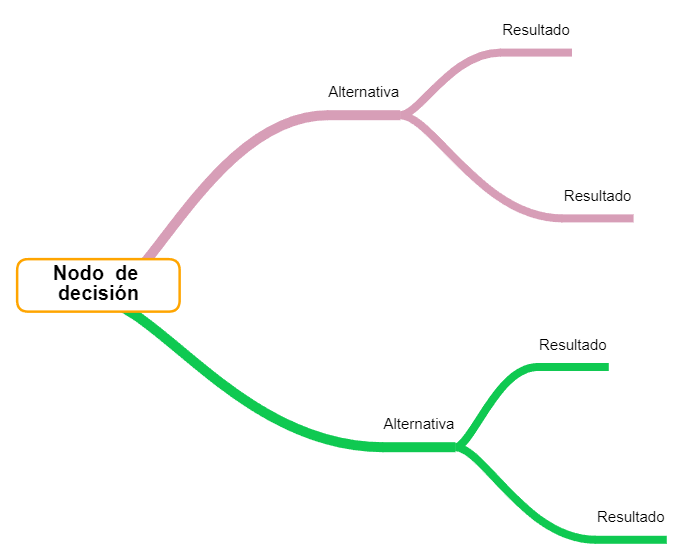
{"id":"58eb2bd2-003c-4d7f-b670-73f19183f003","title":"Nodo de decisión","mindmap":{"root":{"id":"5086d2fa-d376-4975-b815-57c27b8ebd2d","parentId":null,"text":{"caption":"Nodo de decisión","font":{"style":"normal","weight":"bold","decoration":"none","size":20,"color":"#000000"}},"offset":{"x":0,"y":0},"foldChildren":false,"branchColor":"#000000","children":[{"id":"458c0287-4d8b-4025-8073-0d4498ef54eb","parentId":"5086d2fa-d376-4975-b815-57c27b8ebd2d","text":{"caption":"Alternativa","font":{"style":"normal","weight":"normal","decoration":"none","size":15,"color":"#000000"}},"offset":{"x":228.8,"y":-159.2},"foldChildren":false,"branchColor":"#d79eb7","children":[{"id":"65477645-03a8-454a-b4b6-5a5db28fb70c","parentId":"458c0287-4d8b-4025-8073-0d4498ef54eb","text":{"caption":"Resultado","font":{"style":"normal","weight":"normal","decoration":"none","size":15,"color":"#000000"}},"offset":{"x":172.8,"y":-61.6},"foldChildren":false,"branchColor":"#d79eb7","children":[]},{"id":"78e89f5d-259f-4c1e-8d25-c68ff74a87a0","parentId":"458c0287-4d8b-4025-8073-0d4498ef54eb","text":{"caption":"Resultado","font":{"style":"normal","weight":"normal","decoration":"none","size":15,"color":"#000000"}},"offset":{"x":234.390625,"y":104.1875},"foldChildren":false,"branchColor":"#d79eb7","children":[]}]},{"id":"706f7fad-194f-43af-89ba-bf4be7f70b34","parentId":"5086d2fa-d376-4975-b815-57c27b8ebd2d","text":{"caption":"Alternativa","font":{"style":"normal","weight":"normal","decoration":"none","size":15,"color":"#000000"}},"offset":{"x":284,"y":172.8},"foldChildren":false,"branchColor":"#0fc951","children":[{"id":"06ffe144-7cee-4abb-963c-6f1de4deab21","parentId":"706f7fad-194f-43af-89ba-bf4be7f70b34","text":{"caption":"Resultado","font":{"style":"normal","weight":"normal","decoration":"none","size":15,"color":"#000000"}},"offset":{"x":154.4,"y":-79.2},"foldChildren":false,"branchColor":"#0fc951","children":[]},{"id":"401921ea-3ad1-42ca-b938-8e20f3f910e4","parentId":"706f7fad-194f-43af-89ba-bf4be7f70b34","text":{"caption":"Resultado","font":{"style":"normal","weight":"normal","decoration":"none","size":15,"color":"#000000"}},"offset":{"x":212.390625,"y":93.59375},"foldChildren":false,"branchColor":"#0fc951","children":[]}]}]}},"dates":{"created":1666721546512,"modified":1666721893203},"dimensions":{"x":4000,"y":2000},"autosave":false}
Un ejemplo es el problema de clasificar correctamente la variedad de la flor iris a partir del ancho y largo de los pétalos y sépalos.
Hay tres variedades de flor iris: setosa, versicolor y virginica.
Este conjunto de datos tiene 150 muestras:

La regresión lineal es un algoritmo supervisado de Machine Learning.
En función de unos datos en un diagrama de X e Y, se traza una línea que indicará la tendencia de dichos valores.
La fórmula de la recta es la siguiente:
Y= m X+b
Donde Y es el resultado, X es la variable, m la pendiente (o coeficiente) de la recta y b la constante.
En el ejemplo se obtienen las ventas previsibles en julio por la recta de regresión lineal de los meses anteriores.

En este tipo de aprendizaje automático, se almacenan los ejemplos de entrenamiento y, cuando se quiere clasificar un nuevo objeto, se extraen los elementos parecidos y se usan los datos de estos para clasificar al nuevo objeto. Se agregan nuevos datos comparando su similitud con las muestras ya existe antes para encontrar “la mejor pareja” o "vecino próximo" y hacer la predicción.
El clustering usa algoritmos matemáticos que permite agrupar conjunto de objetos no etiquetados para luego, conseguir crear subgrupos de datos llamados Clusters.
Gracias a su implementación, el sistema puede analizar los datos, realizar la tarea y encontrar los posibles errores dentro de su funcionamiento.
En el ejemplo de la imagen el algoritmo puede encontrar tres grupos bien diferenciados:

Es el sistema que más éxito ha tenido y que desarrollaremos en los siguientes puntos.
Por fin hemos llegado a las redes neuronales que son el sistema que más éxito esta teniendo en la actualidad a la hora de aplicar la IA en múltiples campos.
El Deep Learning utiliza un tipo de red neuronal que funciona por capas jerarquizadas. La primera capa se centra en aprender un concepto básico, la segunda capa en algo más complejo, y así, capa a capa, va profundizando hasta alcanzar el resultado deseado:
Por fin hemos llegado a las redes neuronales que son el sistema que más éxito esta teniendo en la actualidad a la hora de aplicar la IA en múltiples campos.
El Deep Learning utiliza un tipo de red neuronal que funciona por capas jerarquizadas. La primera capa se centra en aprender un concepto básico, la segunda capa en algo más complejo, y así, capa a capa, va profundizando hasta alcanzar el resultado deseado. Cada capa está formada por nodos llamados perceptrones o neuronas por similitud con la neuronas humanas.
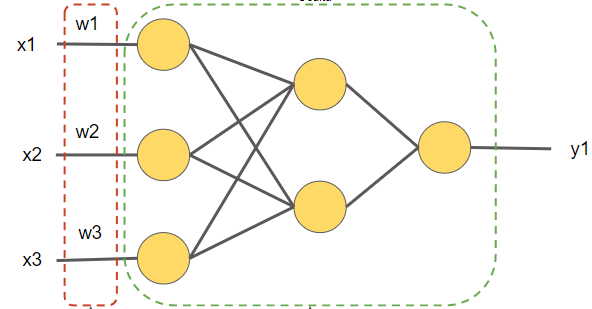
La red neuronal que equivaldría a la de muestra máquina sería la siguiente en la que cada neurona equivaldría a uno de los potenciómetros de la máquina :

En una red neuronal puede haber sólo una capa o varias capas, llamándose capas ocultas a las que están entre la capa de entrada y la capa de salida.
 Inventado en 1957 Frank Rosenblatt basándose en los primeros conceptos de neuronas artificiales, propuso la “regla de aprendizaje del perceptrón”.
Inventado en 1957 Frank Rosenblatt basándose en los primeros conceptos de neuronas artificiales, propuso la “regla de aprendizaje del perceptrón”.
Un perceptrón es una neurona artificial, y, por tanto, una unidad de red neuronal. El perceptrón efectúa cálculos para detectar características o tendencias en los datos de entrada. Cada entrada tiene un peso.
La salida "y" es una función matemática que depende del producto de las variables de entrada "X", de sus pesos "W" y de una variable independiente de ajuste llamada sesgo "b" (bies en inglés) para que la función no esté condicionada a pasar por el origen y se ajuste mejor a la realidad:
y = W1 X1 + ... + Wn Xn + b
Ese valor puede ser positivo o negativo. La neurona artificial se activa si el valor es positivo. Solo se activa si el peso calculado de los datos de entrada supera un umbral determinado.
 El resultado predicho se compara con el resultado conocido. En caso de diferencia, el error se retropropaga para permitir ajustar los pesos, como cuando regulábamos los potenciómetros para que la salida se ajustara cada vez más cerca a la deseada.
El resultado predicho se compara con el resultado conocido. En caso de diferencia, el error se retropropaga para permitir ajustar los pesos, como cuando regulábamos los potenciómetros para que la salida se ajustara cada vez más cerca a la deseada.
En resumen, una red neuronal es un conjunto de perceptrones interconectados. Su funcionamiento se basa en operaciones de multiplicación entre dos componentes importantes: las entradas de datos (x) y el peso (w).
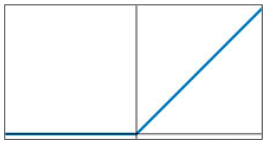
La suma de esa multiplicación se transmite a una función de activación, que determina un valor binario de 0 o 1. Lo que permite clasificar los datos.
Retomando nuestra máquina MPF recordemos que a las salidas obteníamos unas intensidades de corriente con unos valores muy distintos, pero lo único que nos interesaba era si eran mayores o menores a 2 mA, es decir, una salida todo o nada (0 ó 1). Para transformar esos valores dispares en valores más fácilmente tratables vamos a utilizar una hoja de calculo.

En este caso, tras aplicar la función de activación "escalón" se consiguen unos valores de salida binarios y fáciles de tratar.
De esta forma ahora la salida se transforma en:
y = f (W1 X1 + ... + Wn Xn + b)
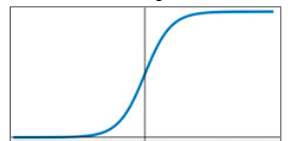
Las funciones de activación en problemas más complejos que no admiten modelos lineales, como el reconocimiento de imágenes, además de adaptar los valores de salida, permite ajustarse mejor a las gráficas en más de dos dimensiones que forman los datos de salida.
Según el Teorema de aproximación universal: bajo una serie de hipótesis, cualquier función continua f puede ser modelada por medio de una red neuronal que conste de una capa oculta y el suficiente número de neuronas.
Algunas de las más conocidas son las siguientes, pero en la actualidad, la que más se utiliza en redes neuronales con capas ocultas es la conocida como función ReLU.

Ahora estamos en condiciones de ver las similitudes entre nuestra máquina del apartado 3 (MPF) y la estructura de una red neuronal. Para hacer la comparativa se ha utilizado un esquema con tres capas y seis neuronas, pero las redes neuronales pueden tener un número variable de capas ocultas y de neuronas en cada capa, tanto mayor cuanto mayor sea la complejidad del modelo que se quiere conseguir.
En los siguientes vídeos hay una explicación más extensa sobre ¿qué es una Red Neuronal? y su funcionamiento:

Nuestra máquina MPF construida con potenciómetros, no es una inteligencia artificial real. En realidad el algoritmo de entrenamiento lo realizamos nosotros que somos los que aportamos "inteligencia" al modelo. Precisamente la gran aportación de las redes neuronales es su capacidad para hacer este aprendizaje por sí mismas.
Supongo que llegaste a un buen resultado, pero por si eres de los que se rinden pronto, en la imagen puedes ver un "modelo" con potenciómetros ajustados que da un buen resultado.
Recupera tu máquina y puedes probarlo.
Para conseguir alcanzar una meta es importante que seas un buen o buena estratega. Es decir, tener métodos, técnicas, “trucos” para llegar antes o de forma más fácil donde tú quieres.
Ahora te voy a enseñar una estrategia, ¡Aprovéchala para alcanzar tu reto!
El nombre de la estrategia es identificar ideas principales y secundarias. Para trabajar con la información que has visto y poder elegir cuál es la más importante es necesario aprender a extraer las ideas principales y secundarias de un texto. Esto te ayudará a comprender mejor la información, encontrar rápidamente las ideas importantes y poder compartirlas con tus compañeras y compañeros.
Podrás encontrar todo lo que necesitas sobre esta estrategia en el siguiente enlace a la guía de la competencia de aprender a aprender.
Tómate el tiempo que necesites y recuerda que siempre puedes preguntarle al docente o a algún compañero o compañera cuando no entiendas algo.
¡Ánimo, seguro que lo haces genial!
¡Cuanta información nueva!
 Es el momento de identificar y extraer las ideas y los datos principales de los textos anteriores y realizar un análisis comparativo de otras informaciones que puedas encontrar en internet.
Es el momento de identificar y extraer las ideas y los datos principales de los textos anteriores y realizar un análisis comparativo de otras informaciones que puedas encontrar en internet.
Realiza un esquema, diagrama conceptual o infografía con los datos de los apartados anteriores. También puedes completarlos con informaciones procedentes de búsquedas en Internet.
Puedes realizarlo en el cuaderno, con alguna aplicación o página en el ordenador.
¡Adelante! ¡Seguro que lo haces genial!
Hola soy Alisa, una inteligencia artificial entrenada para comprobar tus conocimientos sobre Machine Learning.
Voy a realizar una serie de preguntas para ver tu nivel de aprendizaje supervisado.
Obra publicada con Licencia Creative Commons Reconocimiento No comercial Compartir igual 4.0
{kind=link}
{kind=link}
{kind=link}
{kind=link}